지도학습(Supervised Learning) : 정답을 알려주며 학습하는 것.
고양이 사진을 주고(input data), 이 사진은 고양이(정답지 - label data)야.
사자 사진을 주고, 이 사진은 사자야. 라고 알려주는 학습 방식
회귀 : 어떤 데이터들의 특징(feature)을 토대로 값을 예측
분류 : 이진 분류, 다중 분류
K-최근접 이웃(k-Nearest Neigbors)
선형회귀(Linear Regression)
로지스틱 회귀(Logistic Regression)
서포트 벡터 머신(SVM, Support Vector Machine)
결정 트리(Decision Tree)와 랜덤 포레스트(Random Forest)
신경망 (Neural Network)
비지도학습(Unsupervised Learning) : 정답을 알려주지 않고(label 없음), 비슷한 데이터들을 군집화
군집화, 동물이 '무엇' 이라고 기계가 정의는 할 수 없지만 비슷한 단위로 군집화
강화학습(Reinforcement Learning)
상과 벌이라는 보상(reward)을 주며 상을 최대화 하고 벌을 최소화 하도록 강화 학습하는 방식
회귀선 : 주어진 데이터를 대표하는 하나의 직선
회귀식 : 회귀선을 함수로 표현한 것
단순선형 회귀분석 : y = wx + b인 회귀식에서 x가 1개
잔차 : 관측값의 y와 예측값의 y간의
최소제곱법 : 잔차의 제곱의 합이 최소가 되도록 회귀계수를 구함
회귀
소득이 증가하면 소비도 증가. 어떤 변수가 다른 변수에 영향을 준다면 두 변수 사이에 선형관계가 있다고 할 수 있음.
두 변수 사이에 일대일로 대응되는 확률적, 통계적 상관성을 찾는 알고리즘을 Simple Linear Regression 이라고 함. 지도학습
변수 X와 Y에 대한 정보를 가지고 일차 방정식의 계수 a,b를 찾는 과정이 단순회귀분석 알고리즘
In [1]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline import warnings warnings.filterwarnings('ignore')
df = pd.read_csv('auto-mpg.csv') #, header=None df.columns = ['mpg','cylinders','displacement','horsepower', 'weight','acceleration','model year','origin','name'] df.head() |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
Out[1]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 3열 선택3열 다음에 열 추가
- 4열 선택4열 다음에 열 추가
- 5열 선택5열 다음에 열 추가
- 6열 선택6열 다음에 열 추가
- 7열 선택7열 다음에 열 추가
- 8열 선택8열 다음에 열 추가
- 9열 선택9열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
- 4행 선택4행 다음에 행 추가
- 5행 선택5행 다음에 행 추가
열 너비 조절
행 높이 조절
|
|
mpg |
cylinders |
displacement |
horsepower |
weight |
acceleration |
model year |
origin |
name |
|
0 |
15.0 |
8 |
350.0 |
165.0 |
3693.0 |
11.5 |
70 |
1 |
buick skylark 320 |
|
1 |
18.0 |
8 |
318.0 |
150.0 |
3436.0 |
11.0 |
70 |
1 |
plymouth satellite |
|
2 |
16.0 |
8 |
304.0 |
150.0 |
3433.0 |
12.0 |
70 |
1 |
amc rebel sst |
|
3 |
17.0 |
8 |
302.0 |
140.0 |
3449.0 |
10.5 |
70 |
1 |
ford torino |
|
4 |
15.0 |
8 |
429.0 |
198.0 |
4341.0 |
10.0 |
70 |
1 |
ford galaxie 500 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
In [2]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
# horsepower 열의 자료형 변경(문자->숫자) df['horsepower'].replace('?', np.nan, inplace=True) df.dropna(subset=['horsepower'], axis=0, inplace=True) #누락 데이터 행 삭제 df['horsepower'] = df['horsepower'].astype('float')
#저장 df.to_pickle('auto-mpg.pkl')
#분석에 활용할 열(속성)을 선택(연비, 실린더, 출력, 중량) ndf=df[['mpg','cylinders','horsepower', 'weight']] display(ndf.head()) |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 3열 선택3열 다음에 열 추가
- 4열 선택4열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
- 4행 선택4행 다음에 행 추가
- 5행 선택5행 다음에 행 추가
열 너비 조절
행 높이 조절
|
|
mpg |
cylinders |
horsepower |
weight |
|
0 |
15.0 |
8 |
165.0 |
3693.0 |
|
1 |
18.0 |
8 |
150.0 |
3436.0 |
|
2 |
16.0 |
8 |
150.0 |
3433.0 |
|
3 |
17.0 |
8 |
140.0 |
3449.0 |
|
4 |
15.0 |
8 |
198.0 |
4341.0 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
In [3]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
# seaborn pairplot으로 두 변수 간의 모든 경우의 수 그리기 sns.pairplot(ndf) plt.show() plt.close() |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제

대표사진 삭제
사진 설명을 입력하세요.
In [4]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
#속성(변수) 선택 X = ndf[['weight']] #독립변수 X y = ndf['mpg'] #종속변수 Y
# train data 와 test data로 구분(7:3) 비율 from sklearn.model_selection import train_test_split
#이 함수를 이용해서 트레인 셋을 얻는다. X_train, X_test, y_train, y_test = train_test_split(X, #독립변수 y, #종속변수 test_size=0.3, #테스트 값 비율 random_state=10) #랜덤 추출 값
print('train data 개수:', len(X_train)) print() print('test data 개수:', len(X_test)) |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
train data 개수: 273 test data 개수: 118
In [5]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
# sklearn 라이브러리에서 선형회귀분석 모듈 가져오기 from sklearn.linear_model import LinearRegression # 알고리즘(단순선형회귀) 임포트
# 단순회귀분석 모형 객체 생성 (Simple Linear Regression) - 상황에 따라 알맞는 모델을 사용해야 한다. lr = LinearRegression()
# train data를 가지고 모형 학습 lr.fit(X_train, y_train) # 학습용 데이터로 fit 시킨다(학습시킨다). 독립변수와 종속변수를 이용하여 학습 # 학습을 해서 오차를 최소로 하는 y=ax+b 에서 a, b를 찾아준다. # 학습된 데이터는 lr에 저장 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
Out[5]:
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
In [6]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
# 학습을 마친 모형에 test data를 적용하여 결정계수(R-제곱) 계산 # 결정계수 값이 클수록 모형의 예측 성능이 좋다고 판단 # 회귀모델에 대한 평가 : MSE, RMSE, R_Square
r_square = lr.score(X_test, y_test) # score를 통해 점수를 계산해서 정확도 검증(검증용 데이터를 넣어서 검증) print(r_square) # 이 모델에서는 r스퀘어를 사용한다. (설명력이 얼마나 있는지 판단.- 비교적 간단하기 때문에 r_square 사용.) # 분산의 크기를 가지고 평가. |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
0.7035812683047353
In [7]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
# 회귀식의 기울기 print('기울기 a:', lr.coef_) print()
# 회귀식의 y절편 print('y절편 b:', lr.intercept_) print()
# 모형에 전체 X 데이터를 입력하여 예측한 값 y_hat을 실제 값 y와 비교 y_hat = lr.predict(X) # lr을 이용해서 X를 대입했을 때 예측 type(y_hat) |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
기울기 a: [-0.00770318] y절편 b: 46.60392617148081
Out[7]:
numpy.ndarray
In [8]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
y.plot(kind='hist') # y값에 대한 히스토그램 (실제 y값) y=ndf['mpg'] type(y) |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
Out[8]:
pandas.core.series.Series

대표사진 삭제
사진 설명을 입력하세요.
In [9]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
y_hat = pd.Series(y_hat) print(type(y_hat)) y_hat.plot(kind='hist') # 실제 분포(y)하고 예측해서 나온 값(y_hat)을 비교 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
<class 'pandas.core.series.Series'>
Out[9]:
<matplotlib.axes._subplots.AxesSubplot at 0x1dc4ee48948>

대표사진 삭제
사진 설명을 입력하세요.
In [10]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
# 실제 값은 왼쪽으로 편향되어 있고 예측값은 반대로 오른쪽으로 편중되는 경향을 보임. # 모형의 모차를 줄일 필요가 있어 보임. plt.figure(figsize=(15,5)) ax1 = sns.distplot(y, hist=False, label='y') # ax2 = sns.distplot(y_hat, hist=False, label='y_hat', ax=ax1) ax2 = sns.distplot(y_hat, hist=False, label='y_hat') plt.show() plt.close() |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제

대표사진 삭제
사진 설명을 입력하세요.
다항 회귀분석
직선보다 곡선으로 설명하는 것이 적합할 경우 다항 함수를 사용하면 복잡한 곡선 형태의 회귀선을 표현할 수 있음
2차 함수 이상의 다항 함수를 이용하여 두 변수 간의 선형관계를 설명화는 알고리즘
다항 회귀도 선형회귀임. 선형/비선형 회귀를 나누는 기준은 회귀계수가 선형/비선형인지에 따르며 독립변수의 선형/비선형 여부와는 무관
In [11]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
df = pd.read_pickle('auto-mpg.pkl') #분석에 활용할 열(속성)을 선택 (연비, 실린더, 출력, 중량) ndf = df[['mpg', 'cylinders', 'horsepower', 'weight']] ndf.head() |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
Out[11]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 3열 선택3열 다음에 열 추가
- 4열 선택4열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
- 4행 선택4행 다음에 행 추가
- 5행 선택5행 다음에 행 추가
열 너비 조절
행 높이 조절
|
|
mpg |
cylinders |
horsepower |
weight |
|
0 |
15.0 |
8 |
165.0 |
3693.0 |
|
1 |
18.0 |
8 |
150.0 |
3436.0 |
|
2 |
16.0 |
8 |
150.0 |
3433.0 |
|
3 |
17.0 |
8 |
140.0 |
3449.0 |
|
4 |
15.0 |
8 |
198.0 |
4341.0 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
In [12]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
#속성(변수) 선택 X = ndf[['weight']] #독립변수 X , 데이터프레임형태로 저장 y = ndf['mpg'] #종속변수 y, 시리즈 형태로 저장
# train data 와 test data로 구분(7:3) 비율 from sklearn.model_selection import train_test_split
#이 함수를 이용해서 트레인 셋을 얻는다. X_train, X_test, y_train, y_test = train_test_split(X, #독립변수 y, #종속변수 test_size=0.3, #테스트 값 비율 random_state=10) #랜덤 추출 값
print('훈련데이터 : ', X_train.shape) print('검증데이터 : ', X_test.shape) print('훈련데이터 : ', y_train.shape) print('검증데이터 : ', y_test.shape) X_train.head() |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
훈련데이터 : (273, 1) 검증데이터 : (118, 1) 훈련데이터 : (273,) 검증데이터 : (118,)
Out[12]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
- 4행 선택4행 다음에 행 추가
- 5행 선택5행 다음에 행 추가
열 너비 조절
행 높이 조절
|
|
weight |
|
276 |
3410.0 |
|
282 |
3265.0 |
|
356 |
2615.0 |
|
341 |
2385.0 |
|
289 |
4054.0 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
In [13]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
# 다항회귀분석 모형 - sklearn 사용
# sklearn 라이브러리에서 필요한 모듈 가져오기 from sklearn.linear_model import LinearRegression #선형 회귀분석 from sklearn.preprocessing import PolynomialFeatures #다항식 변환
# 다항식 변환 poly = PolynomialFeatures(degree=2) #2차항 적용, 객체 생성 X_train_poly = poly.fit_transform(X_train) #X_train 데이터를 2차항으로 변형(단항 -> 다항으로 바꾸는 기능)
print('원 데이터:', X_train.shape) print('2차항 변환 데이터:', X_train_poly.shape) X_train_poly |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
원 데이터: (273, 1) 2차항 변환 데이터: (273, 3)
Out[13]:
array([[1.0000000e+00, 3.4100000e+03, 1.1628100e+07], [1.0000000e+00, 3.2650000e+03, 1.0660225e+07], [1.0000000e+00, 2.6150000e+03, 6.8382250e+06], [1.0000000e+00, 2.3850000e+03, 5.6882250e+06], [1.0000000e+00, 4.0540000e+03, 1.6434916e+07], [1.0000000e+00, 2.2100000e+03, 4.8841000e+06], [1.0000000e+00, 2.9010000e+03, 8.4158010e+06], [1.0000000e+00, 2.1640000e+03, 4.6828960e+06], [1.0000000e+00, 3.1580000e+03, 9.9729640e+06], [1.0000000e+00, 4.0800000e+03, 1.6646400e+07], [1.0000000e+00, 1.9400000e+03, 3.7636000e+06], [1.0000000e+00, 2.0030000e+03, 4.0120090e+06], [1.0000000e+00, 2.4050000e+03, 5.7840250e+06], [1.0000000e+00, 2.5750000e+03, 6.6306250e+06], [1.0000000e+00, 4.2090000e+03, 1.7715681e+07], [1.0000000e+00, 2.9450000e+03, 8.6730250e+06], [1.0000000e+00, 2.6780000e+03, 7.1716840e+06], [1.0000000e+00, 1.9650000e+03, 3.8612250e+06], [1.0000000e+00, 2.2000000e+03, 4.8400000e+06], [1.0000000e+00, 2.7110000e+03, 7.3495210e+06], [1.0000000e+00, 2.5450000e+03, 6.4770250e+06], [1.0000000e+00, 2.0500000e+03, 4.2025000e+06], [1.0000000e+00, 3.4250000e+03, 1.1730625e+07], [1.0000000e+00, 3.2880000e+03, 1.0810944e+07], [1.0000000e+00, 2.2650000e+03, 5.1302250e+06], [1.0000000e+00, 2.6720000e+03, 7.1395840e+06], [1.0000000e+00, 2.6940000e+03, 7.2576360e+06], [1.0000000e+00, 4.2150000e+03, 1.7766225e+07], [1.0000000e+00, 2.3790000e+03, 5.6596410e+06], [1.0000000e+00, 4.3540000e+03, 1.8957316e+07], [1.0000000e+00, 3.9400000e+03, 1.5523600e+07], [1.0000000e+00, 3.5300000e+03, 1.2460900e+07], [1.0000000e+00, 2.6200000e+03, 6.8644000e+06], [1.0000000e+00, 3.2050000e+03, 1.0272025e+07], [1.0000000e+00, 4.4990000e+03, 2.0241001e+07], [1.0000000e+00, 2.1550000e+03, 4.6440250e+06], [1.0000000e+00, 3.1690000e+03, 1.0042561e+07], [1.0000000e+00, 4.2740000e+03, 1.8267076e+07], [1.0000000e+00, 2.3750000e+03, 5.6406250e+06], [1.0000000e+00, 2.6700000e+03, 7.1289000e+06], [1.0000000e+00, 2.2790000e+03, 5.1938410e+06], [1.0000000e+00, 1.9630000e+03, 3.8533690e+06], [1.0000000e+00, 2.4510000e+03, 6.0074010e+06], [1.0000000e+00, 2.0740000e+03, 4.3014760e+06], [1.0000000e+00, 1.9850000e+03, 3.9402250e+06], [1.0000000e+00, 2.4080000e+03, 5.7984640e+06], [1.0000000e+00, 2.5110000e+03, 6.3051210e+06], [1.0000000e+00, 3.3600000e+03, 1.1289600e+07], [1.0000000e+00, 1.9950000e+03, 3.9800250e+06], [1.0000000e+00, 3.8800000e+03, 1.5054400e+07], [1.0000000e+00, 2.0000000e+03, 4.0000000e+06], [1.0000000e+00, 4.1540000e+03, 1.7255716e+07], [1.0000000e+00, 3.1900000e+03, 1.0176100e+07], [1.0000000e+00, 1.7950000e+03, 3.2220250e+06], [1.0000000e+00, 2.9300000e+03, 8.5849000e+06], [1.0000000e+00, 2.2020000e+03, 4.8488040e+06], [1.0000000e+00, 3.6130000e+03, 1.3053769e+07], [1.0000000e+00, 2.5820000e+03, 6.6667240e+06], [1.0000000e+00, 3.9000000e+03, 1.5210000e+07], [1.0000000e+00, 4.4220000e+03, 1.9554084e+07], [1.0000000e+00, 2.9500000e+03, 8.7025000e+06], [1.0000000e+00, 3.6930000e+03, 1.3638249e+07], [1.0000000e+00, 2.0650000e+03, 4.2642250e+06], [1.0000000e+00, 4.3250000e+03, 1.8705625e+07], [1.0000000e+00, 1.9370000e+03, 3.7519690e+06], [1.0000000e+00, 2.1300000e+03, 4.5369000e+06], [1.0000000e+00, 2.2780000e+03, 5.1892840e+06], [1.0000000e+00, 2.6350000e+03, 6.9432250e+06], [1.0000000e+00, 3.6050000e+03, 1.2996025e+07], [1.0000000e+00, 2.6700000e+03, 7.1289000e+06], [1.0000000e+00, 4.1000000e+03, 1.6810000e+07], [1.0000000e+00, 4.4980000e+03, 2.0232004e+07], [1.0000000e+00, 3.5250000e+03, 1.2425625e+07], [1.0000000e+00, 2.4010000e+03, 5.7648010e+06], [1.0000000e+00, 4.1290000e+03, 1.7048641e+07], [1.0000000e+00, 2.5420000e+03, 6.4617640e+06], [1.0000000e+00, 2.9100000e+03, 8.4681000e+06], [1.0000000e+00, 2.3350000e+03, 5.4522250e+06], [1.0000000e+00, 1.7550000e+03, 3.0800250e+06], [1.0000000e+00, 2.7000000e+03, 7.2900000e+06], [1.0000000e+00, 3.5200000e+03, 1.2390400e+07], [1.0000000e+00, 3.5740000e+03, 1.2773476e+07], [1.0000000e+00, 3.9620000e+03, 1.5697444e+07], [1.0000000e+00, 4.0420000e+03, 1.6337764e+07], [1.0000000e+00, 2.8150000e+03, 7.9242250e+06], [1.0000000e+00, 3.7850000e+03, 1.4326225e+07], [1.0000000e+00, 3.1390000e+03, 9.8533210e+06], [1.0000000e+00, 3.4250000e+03, 1.1730625e+07], [1.0000000e+00, 3.2210000e+03, 1.0374841e+07], [1.0000000e+00, 1.9680000e+03, 3.8730240e+06], [1.0000000e+00, 3.2450000e+03, 1.0530025e+07], [1.0000000e+00, 2.9450000e+03, 8.6730250e+06], [1.0000000e+00, 3.6720000e+03, 1.3483584e+07], [1.0000000e+00, 1.8450000e+03, 3.4040250e+06], [1.0000000e+00, 4.1650000e+03, 1.7347225e+07], [1.0000000e+00, 2.4900000e+03, 6.2001000e+06], [1.0000000e+00, 3.0600000e+03, 9.3636000e+06], [1.0000000e+00, 2.7200000e+03, 7.3984000e+06], [1.0000000e+00, 2.1640000e+03, 4.6828960e+06], [1.0000000e+00, 3.4330000e+03, 1.1785489e+07], [1.0000000e+00, 4.2570000e+03, 1.8122049e+07], [1.0000000e+00, 2.9650000e+03, 8.7912250e+06], [1.0000000e+00, 2.0650000e+03, 4.2642250e+06], [1.0000000e+00, 2.1580000e+03, 4.6569640e+06], [1.0000000e+00, 2.6600000e+03, 7.0756000e+06], [1.0000000e+00, 3.6450000e+03, 1.3286025e+07], [1.0000000e+00, 2.9000000e+03, 8.4100000e+06], [1.0000000e+00, 3.6510000e+03, 1.3329801e+07], [1.0000000e+00, 3.1500000e+03, 9.9225000e+06], [1.0000000e+00, 2.2200000e+03, 4.9284000e+06], [1.0000000e+00, 2.7350000e+03, 7.4802250e+06], [1.0000000e+00, 2.1500000e+03, 4.6225000e+06], [1.0000000e+00, 3.4390000e+03, 1.1826721e+07], [1.0000000e+00, 2.5420000e+03, 6.4617640e+06], [1.0000000e+00, 4.4250000e+03, 1.9580625e+07], [1.0000000e+00, 3.5630000e+03, 1.2694969e+07], [1.0000000e+00, 4.6540000e+03, 2.1659716e+07], [1.0000000e+00, 4.2370000e+03, 1.7952169e+07], [1.0000000e+00, 4.0960000e+03, 1.6777216e+07], [1.0000000e+00, 2.1300000e+03, 4.5369000e+06], [1.0000000e+00, 2.1250000e+03, 4.5156250e+06], [1.0000000e+00, 1.8250000e+03, 3.3306250e+06], [1.0000000e+00, 2.1450000e+03, 4.6010250e+06], [1.0000000e+00, 3.0390000e+03, 9.2355210e+06], [1.0000000e+00, 2.2230000e+03, 4.9417290e+06], [1.0000000e+00, 2.6050000e+03, 6.7860250e+06], [1.0000000e+00, 3.0120000e+03, 9.0721440e+06], [1.0000000e+00, 3.3800000e+03, 1.1424400e+07], [1.0000000e+00, 3.8400000e+03, 1.4745600e+07], [1.0000000e+00, 3.2700000e+03, 1.0692900e+07], [1.0000000e+00, 4.6680000e+03, 2.1790224e+07], [1.0000000e+00, 1.9450000e+03, 3.7830250e+06], [1.0000000e+00, 2.9500000e+03, 8.7025000e+06], [1.0000000e+00, 2.2280000e+03, 4.9639840e+06], [1.0000000e+00, 2.1240000e+03, 4.5113760e+06], [1.0000000e+00, 3.4150000e+03, 1.1662225e+07], [1.0000000e+00, 4.2940000e+03, 1.8438436e+07], [1.0000000e+00, 2.0450000e+03, 4.1820250e+06], [1.0000000e+00, 4.6380000e+03, 2.1511044e+07], [1.0000000e+00, 1.8500000e+03, 3.4225000e+06], [1.0000000e+00, 2.5560000e+03, 6.5331360e+06], [1.0000000e+00, 2.7020000e+03, 7.3008040e+06], [1.0000000e+00, 3.0150000e+03, 9.0902250e+06], [1.0000000e+00, 4.3350000e+03, 1.8792225e+07], [1.0000000e+00, 3.6300000e+03, 1.3176900e+07], [1.0000000e+00, 2.9840000e+03, 8.9042560e+06], [1.0000000e+00, 3.4200000e+03, 1.1696400e+07], [1.0000000e+00, 1.8670000e+03, 3.4856890e+06], [1.0000000e+00, 3.2500000e+03, 1.0562500e+07], [1.0000000e+00, 2.1230000e+03, 4.5071290e+06], [1.0000000e+00, 2.2150000e+03, 4.9062250e+06], [1.0000000e+00, 2.1100000e+03, 4.4521000e+06], [1.0000000e+00, 2.8700000e+03, 8.2369000e+06], [1.0000000e+00, 2.1000000e+03, 4.4100000e+06], [1.0000000e+00, 3.1210000e+03, 9.7406410e+06], [1.0000000e+00, 4.4560000e+03, 1.9855936e+07], [1.0000000e+00, 3.2780000e+03, 1.0745284e+07], [1.0000000e+00, 2.2340000e+03, 4.9907560e+06], [1.0000000e+00, 3.2100000e+03, 1.0304100e+07], [1.0000000e+00, 2.0700000e+03, 4.2849000e+06], [1.0000000e+00, 2.5950000e+03, 6.7340250e+06], [1.0000000e+00, 3.7300000e+03, 1.3912900e+07], [1.0000000e+00, 2.1300000e+03, 4.5369000e+06], [1.0000000e+00, 2.1080000e+03, 4.4436640e+06], [1.0000000e+00, 4.3800000e+03, 1.9184400e+07], [1.0000000e+00, 2.3500000e+03, 5.5225000e+06], [1.0000000e+00, 4.3630000e+03, 1.9035769e+07], [1.0000000e+00, 4.7460000e+03, 2.2524516e+07], [1.0000000e+00, 2.7550000e+03, 7.5900250e+06], [1.0000000e+00, 1.9750000e+03, 3.9006250e+06], [1.0000000e+00, 2.4340000e+03, 5.9243560e+06], [1.0000000e+00, 1.8340000e+03, 3.3635560e+06], [1.0000000e+00, 1.7950000e+03, 3.2220250e+06], [1.0000000e+00, 2.7950000e+03, 7.8120250e+06], [1.0000000e+00, 3.4650000e+03, 1.2006225e+07], [1.0000000e+00, 2.0190000e+03, 4.0763610e+06], [1.0000000e+00, 1.7730000e+03, 3.1435290e+06], [1.0000000e+00, 2.8330000e+03, 8.0258890e+06], [1.0000000e+00, 2.1880000e+03, 4.7873440e+06], [1.0000000e+00, 3.1400000e+03, 9.8596000e+06], [1.0000000e+00, 3.8300000e+03, 1.4668900e+07], [1.0000000e+00, 3.4490000e+03, 1.1895601e+07], [1.0000000e+00, 2.6480000e+03, 7.0119040e+06], [1.0000000e+00, 1.8360000e+03, 3.3708960e+06], [1.0000000e+00, 2.6390000e+03, 6.9643210e+06], [1.0000000e+00, 1.9900000e+03, 3.9601000e+06], [1.0000000e+00, 3.2820000e+03, 1.0771524e+07], [1.0000000e+00, 2.0750000e+03, 4.3056250e+06], [1.0000000e+00, 2.1900000e+03, 4.7961000e+06], [1.0000000e+00, 5.1400000e+03, 2.6419600e+07], [1.0000000e+00, 2.2650000e+03, 5.1302250e+06], [1.0000000e+00, 2.2880000e+03, 5.2349440e+06], [1.0000000e+00, 4.1900000e+03, 1.7556100e+07], [1.0000000e+00, 2.8350000e+03, 8.0372250e+06], [1.0000000e+00, 4.1400000e+03, 1.7139600e+07], [1.0000000e+00, 2.7450000e+03, 7.5350250e+06], [1.0000000e+00, 2.2650000e+03, 5.1302250e+06], [1.0000000e+00, 3.7610000e+03, 1.4145121e+07], [1.0000000e+00, 3.4590000e+03, 1.1964681e+07], [1.0000000e+00, 2.0510000e+03, 4.2066010e+06], [1.0000000e+00, 3.9880000e+03, 1.5904144e+07], [1.0000000e+00, 3.3650000e+03, 1.1323225e+07], [1.0000000e+00, 4.6990000e+03, 2.2080601e+07], [1.0000000e+00, 2.1250000e+03, 4.5156250e+06], [1.0000000e+00, 2.8300000e+03, 8.0089000e+06], [1.0000000e+00, 1.9250000e+03, 3.7056250e+06], [1.0000000e+00, 2.2550000e+03, 5.0850250e+06], [1.0000000e+00, 2.1440000e+03, 4.5967360e+06], [1.0000000e+00, 2.7250000e+03, 7.4256250e+06], [1.0000000e+00, 4.3410000e+03, 1.8844281e+07], [1.0000000e+00, 4.1410000e+03, 1.7147881e+07], [1.0000000e+00, 2.4080000e+03, 5.7984640e+06], [1.0000000e+00, 3.1550000e+03, 9.9540250e+06], [1.0000000e+00, 3.9400000e+03, 1.5523600e+07], [1.0000000e+00, 3.9550000e+03, 1.5642025e+07], [1.0000000e+00, 2.5650000e+03, 6.5792250e+06], [1.0000000e+00, 4.4570000e+03, 1.9864849e+07], [1.0000000e+00, 2.2460000e+03, 5.0445160e+06], [1.0000000e+00, 4.0980000e+03, 1.6793604e+07], [1.0000000e+00, 2.8680000e+03, 8.2254240e+06], [1.0000000e+00, 2.3800000e+03, 5.6644000e+06], [1.0000000e+00, 2.2950000e+03, 5.2670250e+06], [1.0000000e+00, 2.3000000e+03, 5.2900000e+06], [1.0000000e+00, 2.9330000e+03, 8.6024890e+06], [1.0000000e+00, 2.3700000e+03, 5.6169000e+06], [1.0000000e+00, 3.5700000e+03, 1.2744900e+07], [1.0000000e+00, 3.8210000e+03, 1.4600041e+07], [1.0000000e+00, 2.6400000e+03, 6.9696000e+06], [1.0000000e+00, 4.9510000e+03, 2.4512401e+07], [1.0000000e+00, 1.8350000e+03, 3.3672250e+06], [1.0000000e+00, 3.7250000e+03, 1.3875625e+07], [1.0000000e+00, 1.9150000e+03, 3.6672250e+06], [1.0000000e+00, 3.3810000e+03, 1.1431161e+07], [1.0000000e+00, 2.6340000e+03, 6.9379560e+06], [1.0000000e+00, 2.1100000e+03, 4.4521000e+06], [1.0000000e+00, 2.3000000e+03, 5.2900000e+06], [1.0000000e+00, 4.4640000e+03, 1.9927296e+07], [1.0000000e+00, 3.8970000e+03, 1.5186609e+07], [1.0000000e+00, 4.3600000e+03, 1.9009600e+07], [1.0000000e+00, 1.9750000e+03, 3.9006250e+06], [1.0000000e+00, 2.1900000e+03, 4.7961000e+06], [1.0000000e+00, 1.6490000e+03, 2.7192010e+06], [1.0000000e+00, 1.9850000e+03, 3.9402250e+06], [1.0000000e+00, 2.3720000e+03, 5.6263840e+06], [1.0000000e+00, 2.1890000e+03, 4.7917210e+06], [1.0000000e+00, 2.1600000e+03, 4.6656000e+06], [1.0000000e+00, 2.4640000e+03, 6.0712960e+06], [1.0000000e+00, 2.6710000e+03, 7.1342410e+06], [1.0000000e+00, 2.2450000e+03, 5.0400250e+06], [1.0000000e+00, 1.8250000e+03, 3.3306250e+06], [1.0000000e+00, 3.3290000e+03, 1.1082241e+07], [1.0000000e+00, 4.1350000e+03, 1.7098225e+07], [1.0000000e+00, 3.6640000e+03, 1.3424896e+07], [1.0000000e+00, 2.3950000e+03, 5.7360250e+06], [1.0000000e+00, 1.9850000e+03, 3.9402250e+06], [1.0000000e+00, 1.9550000e+03, 3.8220250e+06], [1.0000000e+00, 2.6000000e+03, 6.7600000e+06], [1.0000000e+00, 2.9300000e+03, 8.5849000e+06], [1.0000000e+00, 2.5870000e+03, 6.6925690e+06], [1.0000000e+00, 2.1250000e+03, 4.5156250e+06], [1.0000000e+00, 4.9550000e+03, 2.4552025e+07], [1.0000000e+00, 3.0700000e+03, 9.4249000e+06], [1.0000000e+00, 4.0770000e+03, 1.6621929e+07], [1.0000000e+00, 3.8500000e+03, 1.4822500e+07], [1.0000000e+00, 2.7900000e+03, 7.7841000e+06], [1.0000000e+00, 4.2950000e+03, 1.8447025e+07], [1.0000000e+00, 4.6570000e+03, 2.1687649e+07], [1.0000000e+00, 3.1020000e+03, 9.6224040e+06], [1.0000000e+00, 2.0250000e+03, 4.1006250e+06], [1.0000000e+00, 2.8000000e+03, 7.8400000e+06], [1.0000000e+00, 2.7740000e+03, 7.6950760e+06], [1.0000000e+00, 3.3360000e+03, 1.1128896e+07], [1.0000000e+00, 2.3000000e+03, 5.2900000e+06]])
In [14]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
# train data를 가지고 모형 학습 pr = LinearRegression() pr.fit(X_train_poly, y_train) #다항으로 바꿔준 데이터로 학습을 시킨다. # 다항으로 바꾼 독립변수들과, 학습한 y값으로 학습시킨다. (선형회귀법을 사용) # pr에 학습된 모델이 적용된 상태
# 학습을 마친 모형에 test data를 적용하여 결정계수(R-제곱) 계산 # 설계한 모형의 오차가 작다면 R-square가 커지고, 설계한 모형의 오차가 크다면 R-square
X_test_poly = poly.fit_transform(X_test) r_square = pr.score(X_test_poly, y_test) # 학습된 모델을 가지고 스코어링 할 수 있다.(설명력 점수 평가) print(r_square) # 3% 값이 개선된 것을 확인할 수 있다. |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
0.7337822241594427
In [15]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
# train data의 산점도와 test data로 예측한
y_hat_test = pr.predict(X_test_poly) # 다항으로 바꾼 검증용 데이터를 가지고 예측한 값을 y_hat_test에 저장
fig = plt.figure(figsize=(10,5)) ax = fig.add_subplot(1,1,1) # 하나의 그래프를 만들어준다. ax.plot(X_train, y_train, 'o', label='Train Data') # 데이터 분포 # 학습용 데이터를 그래프로 그려준다. ax.plot(X_test, y_hat_test, 'r+', label = 'Predicted Value') #모형이 학습한 회귀선, ax.legend(loc='best') plt.xlabel('weight') plt.ylabel('mpg') plt.show() plt.close() |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
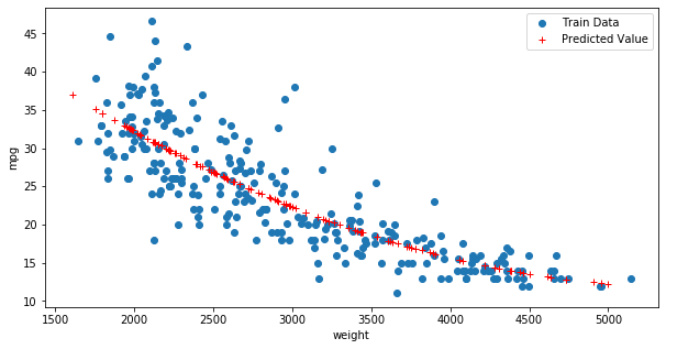
대표사진 삭제
사진 설명을 입력하세요.
In [16]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
# 모형에 전체 X 데이터를 입력하여 예측한 값 y_hat을 실제 값 y와 비교 # 단순 회귀분석 결과와 비교하면 데이터가 어느 한쪽으로 편향되는 경향이 상당히 감소한 것을 확인 X_poly = poly.fit_transform(X) y_hat = pr.predict(X_poly)
plt.figure(figsize=(15,5)) ax1 = sns.distplot(y, hist=False, label='y') # 히스토그램을 보여줄지 말지 선택(True, False) ax2 = sns.distplot(y_hat, hist=False, label='y_hat', ax=ax1) plt.show() plt.close() |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제

대표사진 삭제
사진 설명을 입력하세요.
회귀 평가 지표
MAE : 실제값과 예측값의 차이를 절대값으로 변환해 평균한 것 (절대값으로 하는 것)
MSE : 실제값과 예측값의 차이를 제곱해 평균한 것 (스퀘어 해서 처리)
RMSE : MSE에 루트를 씌운 것(실제 오류 평균보다 커지는 것 보정) (스퀘어를 하니까 다시 루트를 씌운다.)
R square : 분산 기반으로 예측 성능을 평가, 실제 값의 분산 대비 예측값의 분산 비율을 지표로 함 (분산값으로 해서 설명력을 높여주는 것)
분류 - KNN
KNN : k-Nearest-Neighbors의 약칭. 새로운 관측값이 주어지면 가장 속성이 비슷한 이웃을 먼저 찾음
가까운 목표 값과 같은 값으로 분류하여 예측
k값에 따라 예측의 정확도가 달라지므로 적절한 k값을 찾는 것이 중요
★가까운 것 부터 찾고, 범위를 넓혀가며 값을 찾음. 이 때, 다수결에 의해 수가 많은 그룹을 선택하여 묶인다.

대표사진 삭제
사진 설명을 입력하세요.
분류 - SVM
Margin이란 선과 가장 가까운 양 옆 데이터와의 거리
선과 가장 가까운 포인트를 서포트 벡터(Support vector)
데이터를 정확히 분류하는 범위를 먼저 찾고, 그 범위 안에서 Margin을 최대화하는 구분선을 선택
로버스트 하다는 것은 아웃라이어(outlier)의 영향을 받지 않는다는 의미
어느 정도 outlier를 무시하고 최적의 구분선
(가운데를 기준으로 나눴을 때, 나눈 선을 기준으로 데이터와의 거리가 '서포트 벡터'라고 한다)
(나눈다고 하더라고 그 기준을 벗어나는 것들이 존재, 이것이 아웃라이어. 이 때, 로버스트하여 아웃라이어의 영향을 받지 않는다.)

대표사진 삭제
사진 설명을 입력하세요.
분류 - Decision Tree
Decision Tree : 의사결정 나무라는 의미. 트리 구조를 사용, 각 분기점(node) 에는 분석 대상의 속성들이 위치
각 분기점마다 목표 값을 잘 분류할 수 있는 속성을 찾아서 배치
해당 속성이 갖느 값을 이용하여 새로운 가지(branch)를 만듦
최적의 속성을 선택할 때는 다른 종류의 값들이 섞여 있는 정도를 나타내는 Entropy를 주로 활용
Entropy가 낮을 수록 분류가 잘 된 것임

대표사진 삭제
사진 설명을 입력하세요.
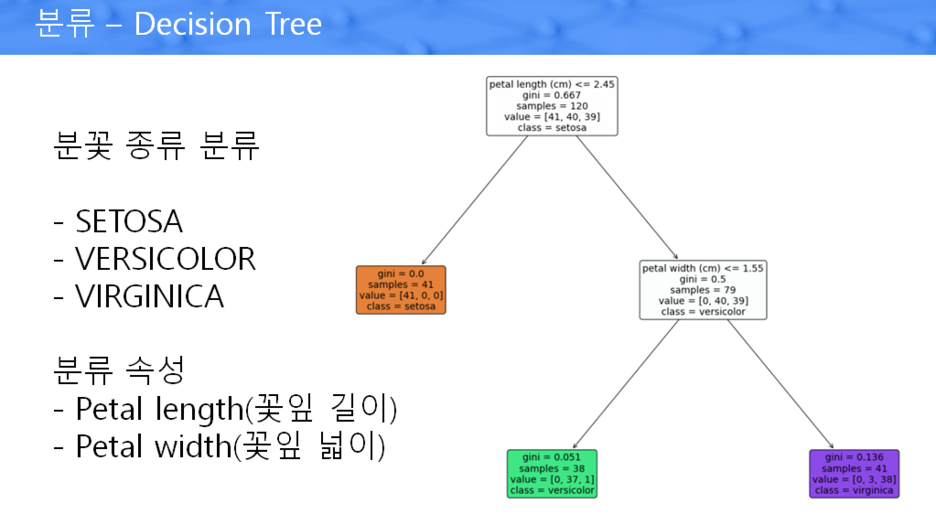
대표사진 삭제
사진 설명을 입력하세요.
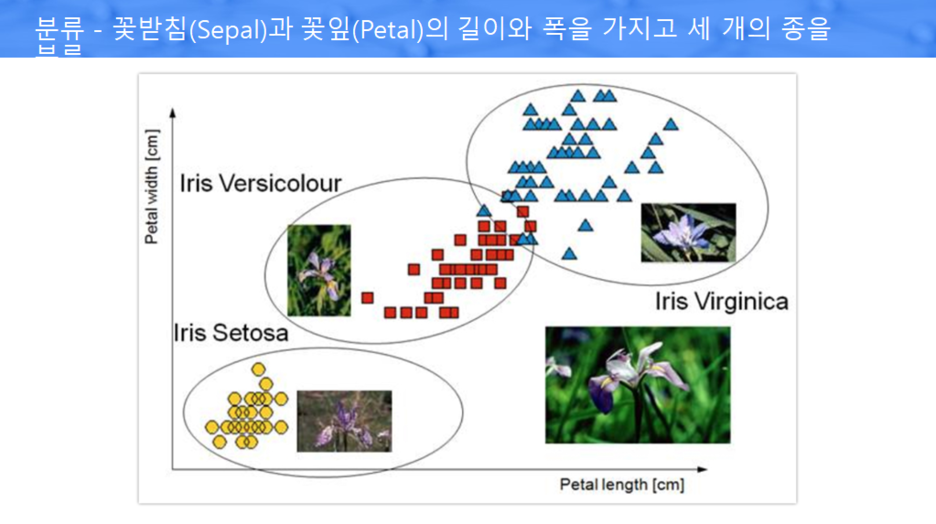
대표사진 삭제
사진 설명을 입력하세요.
분류 - Logistic Regression
분류에 사용하는 회귀분석 종속변수가 범주형이면서 0, 1
일반 회귀모형을 로짓 변환
Odds ratio : 실패에 비해 성공할 확률 p/(1-p)
Logit : Odds에 log를 취한 것

대표사진 삭제
사진 설명을 입력하세요.
분류 - Random Forest
하나의 알고리즘 사용
학습 데이터셋을 랜덤하게 추출하여 모델을 학습
투표방식으로 최빈값으로 결정
배깅 : 학습 데이터에서 랜덤하게 추출 시 중복 허용

대표사진 삭제
사진 설명을 입력하세요.
In [41]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
from sklearn.tree import DecisionTreeClassifier # 분류기 from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split import warnings warnings.filterwarnings('ignore')
# 붓꽃 데이터를 로딩하고 학습과 테스트 데이터 세트로 분리 iris_data = load_iris() display(iris_data.keys()) # columns 값을 볼 수 있다. (feature는 독립변수를 의미) X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, # 8:2 로 나누니까 0.2로 놔준다. random_state=11)
print(iris_data.feature_names) print(iris_data.target_names)
# DecisionTree Claaifier 생성 # dt_clf = DecisionTreeClassifier(random_state=156) # 아무 제약을 걸지 않은 기본 dt_clf = DecisionTreeClassifier(criterion='gini', max_depth=2, random_state=156) # max_depth = 2 는 두번째 단계까지만 만든다. # dt_clf = DecisionTreeClassifier(criterion='gini', max_depth=4, random_state=156) # dt_clf = DecisionTreeClassifier(criterion='gini', max_depth=4, random_state=156)
# criterion='gini' or criterion='entropy' 가능
# DecisionTreeClassifier 학습 dt_clf.fit(X_train, y_train) # 학습용 데이터로 학습을 시킨다. dt_clf는 학습된 모델이 된다. y_hat = dt_clf.predict(X_test) # 학습된 모델(dt_clf)을 토대로 예측(검증 평가용 X_test 데이터를 이용) |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] ['setosa' 'versicolor' 'virginica']
Dicision Tree 파라미터
max_depth : 트리의 최대 깊이 ( 5 단계로 찢어지는것은 max_depth = 5 이다.)
max_features : 최적의 분할을 위해 고려할 최대 피처 개수
max_leaf_nodes : 말단 노드의 최대 개수
min_samples_split : 노드를 분할하기 위한 최소한의 샘플 데이터, 디폴트 2. 작게 설정할 수록 분할되는 노드 증가, 과적합 가능성 증가
min_samples_leaf : 말단 노드가 되기 위한 최소한의 샘플 데이터
In [43]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
# DT 시각화 from sklearn import tree import matplotlib.pyplot as plt %matplotlib inline
plt.figure(figsize=(20,15)) tree.plot_tree(dt_clf, filled=True, # 그림을 그린다. feature_names=iris_data.feature_names, # iris_data가 가지고 있는 데이터를 입력한다. class_names=iris_data.target_names, # iris_data가 가지고 있는 데이터를 입력한다. rounded=True, fontsize=14) # 사각형의 모서리 라운드처리, 글자 사이즈 plt.show() plt.close() # petal length <= 2.45 : 가장 중요한 분류 기준 # petal width <= 1.55 기준 : 두 번째 분류 기준 # 완전히 분리되는 것은 gini(불순도) = 0.0 이다. # entropy 를 통해 모두가 gini = 0.0 이 될 때 까지 # 계속 가지치기를 해서 제일 밑에부분까지 내려가서 너무 미세한부분까지 맞춰지면 일반화된것을 예측하기 어려움 # --> 차원의 저주 # --> 일반화된 예측 모델을 만들어야 한다. # 성능이 부족함(정확도)에도 많이 사용한다. 내부 처리 데이터를 쉽게 확인할 수 있는 장점이 존재. |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제

대표사진 삭제
사진 설명을 입력하세요.
In [49]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
import pandas as pd import numpy as np
pd.set_option('display.max_columns', 15) titanic_df=pd.read_csv('titanic3.csv')
from sklearn.preprocessing import LabelEncoder # Null 처리 함수 def fillna(df): df['age'].fillna(df['age'].mean(), inplace=True) df['cabin'].fillna('N', inplace=True) df['fare'].fillna(df['fare'].mean(), inplace=True) df['embarked'].fillna('N', inplace=True) return df
def drop_features(df): df.drop(['home.dest','boat','body','name','ticket'], axis=1, inplace=True) return df
def format_features(df): df['cabin'] = df['cabin'].str[:1] features = ['cabin','sex','embarked'] for feature in features: le = LabelEncoder() df[feature] = le.fit_transform(df[feature]) return df
def transform_features(df): df = fillna(df) df = drop_features(df) df = format_features(df) return df
t_df = transform_features(titanic_df) display(t_df.head()) display(t_df.columns.values) |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 3열 선택3열 다음에 열 추가
- 4열 선택4열 다음에 열 추가
- 5열 선택5열 다음에 열 추가
- 6열 선택6열 다음에 열 추가
- 7열 선택7열 다음에 열 추가
- 8열 선택8열 다음에 열 추가
- 9열 선택9열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
- 4행 선택4행 다음에 행 추가
- 5행 선택5행 다음에 행 추가
열 너비 조절
행 높이 조절
|
|
pclass |
survived |
sex |
age |
sibsp |
parch |
fare |
cabin |
embarked |
|
0 |
1 |
1 |
0 |
29.00 |
0 |
0 |
211.3375 |
1 |
3 |
|
1 |
1 |
1 |
1 |
0.92 |
1 |
2 |
151.5500 |
2 |
3 |
|
2 |
1 |
0 |
0 |
2.00 |
1 |
2 |
151.5500 |
2 |
3 |
|
3 |
1 |
0 |
1 |
30.00 |
1 |
2 |
151.5500 |
2 |
3 |
|
4 |
1 |
0 |
0 |
25.00 |
1 |
2 |
151.5500 |
2 |
3 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
array(['pclass', 'survived', 'sex', 'age', 'sibsp', 'parch', 'fare', 'cabin', 'embarked'], dtype=object)
In [61]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
from sklearn import preprocessing from sklearn.model_selection import train_test_split
# 독립변수, 종속변수 분리 X = t_df[['pclass', 'sex', 'age', 'sibsp', 'parch', 'fare', 'cabin', 'embarked']] y = t_df['survived']
# 독립변수 정규화(평균 0, 분산1인 표준정규분포) X = preprocessing.StandardScaler().fit(X).transform(X) # StandardScaler : 표준정규분포
# 학습용 데이터와 평가용 데이터를 8:2로 분리 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
print(X_train.shape) # (1047, 8) 80% 데이터 갯수 print(X_test.shape) # (262, 8) 20% 데이터 갯수 print() print(X.mean()) # -4.885320566723378e-17 (0.0 이 17개 있어서 거의 0이라고 보면 된다.)-> 평균 = 0 print(X.std()) # 1.0 표준편차 print(type(y_test)) # <class 'pandas.core.series.Series'> |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
(1047, 8) (262, 8) -4.885320566723378e-17 1.0 <class 'pandas.core.series.Series'>
In [109]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
# Decision Tree from sklearn.metrics import accuracy_score from sklearn.tree import DecisionTreeClassifier
dt_model = DecisionTreeClassifier() # 객체 생성 dt_model.fit(X_train, y_train) # 트레이닝 데이터로 학습 dt_pred = dt_model.predict(X_test) # 검증용 데이터로 예측
print(dt_pred[0:10]) print(y_test.values[0:10])
accuracy = accuracy_score(y_test, dt_pred) print('dt 예측 정확도:',accuracy) # 예측 정확도가 좋지 못하면 재개발 해야함 # 분석용 데이터셋을 잘 만들어서, 중요한 변수들을 뽑아내야 함. |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
[0 1 0 0 0 0 0 1 0 0] [1 0 0 1 0 0 0 1 1 0] dt 예측 정확도: 0.7404580152671756
훈련과정 : R·파이썬 기반 빅데이터 분석 전문가 양성과정
교과목 평가 : 통계학
성명 : 호지수
점수 : 85 / 90 (1번 제외하고 나머지 다 맞았습니다.)
Q1. 모집단의 특성을 의미하며 그리스 문자 뮤(μ), 시그마(σ)로 표현하는 것은 무엇입니까?
답 : 뮤 : 평균, 시그마 : 표준편차 (X)
-> 모수 (O)
Q2. 표본의 특성을 나타내는 수치로 모수를 추정하는데 사용되는 것은 무엇입니까? (표본특성)
답 : 통계량
Q3. "( )은 모수가 평균이 μ이고 표준편차가 σ인 연속확률 분포입니다." ( )에 적합한 용어를 기술하세요.
답 : 정규분포
Q4. "서로 다른 모수값을 가진 집단들을 비교하기 위하여 정규분포를 ( ) 한다." ( )에 적합한 용어를 기술하세요.
답 : 표준화
Q5. "평균값에서 표준편차의 몇 배 정도 떨어져 있다."는 것을 평가하는 수치는?
답 : Z-score
Q6. "표준정규분표에서는 평균 0에서 ±3 범위 내 전체의 ( )% 의 데이터가 있다." ()을 채우세요.
답 : 99%
Q7. "좌표평면을 펼쳐놓고 x 축은 변인 x 를, y 축은 변인 y 를 나타내게 한 뒤 각각의 관찰값들을 산점도 형태로 찍어놓으면, 그 결과 두 변인이 어떤 관계가 있는지 시각적으로 나타나게 된다. 양(+)의 상관이 나타날 경우 관찰값들은 우상향하는 방향으로 모이게 되고, 음(-)의 상관이 나타날 경우 관찰값들은 우하향하는 방향으로 모이게 된다. 관찰값들이 더욱 빽빽하게 밀집해서 모이는 경우가 있고, 조금은 대충대충(?) 흩어져 분포하는 경우가 있는데,전자의 경우 ( )가 높다고 말할 수 있고, 후자의 경우 ( )가 낮다고 말할 수 있다." ( )을 채우세요.
답 : 상관관계
Q8. 데이터프레임의 기술 통계 정보를 요약하는 함수는?
답 : .describe()
Q8.다음중 연속형으로 사용될 수 없는 데이터는? ( )
키
몸무게
성적
국가
답 : 없음. 4가지 모두 연속형과 범주형으로 사용 가능하다.
키 : 큰키, 작은 키(원하는 대로 지정하여 범주화 가능, 수치별로 연속형도 가능)
몸무게 : 저체중, 보통체중, 고체중으로 범주화도 가능하며, 수치별로 연속형도 가능
성적 : 등급별(범주화), 수치별(연속형)
국가 : 숫자를 부여하여 연속형으로도 가능하며, 대륙별로 범주화도 가능하다.
(정답에 가장 가까운 것은 4번 국가)
Q9. 다음중 범주형으로 사용될 가능성이 가장 적은 데이터는? ( )
1.키 2.몸무게 3.성적 4.자동차 생산량
답 : 4번(자동차 생산량을 범주화하는 것은 불가능 하기 때문, 키, 몸무게, 성적은 비만도, 등급 등에 따라 나눌 수 있음)
Q10. H사는 자동차 생산라인을 3개를 가동하고 있다. 최근 6개월간 월별 생산대수의 평균과 표준편차를 조사한 결과 아래와 같았다. H사 A, B, C 라인중 가장 안전성이 있는 라인은 어느 라인인가? ( )
A라인 - 평균 1000, 표준편차 10 B라인 - 평균 1000, 표준편차 5 C라인 - 평균 1000, 표준편차 15
답 : B 라인 : 평균은 모두 동일할 때, 표준편차가 5로 가장 작은 산포를 가지고 있기 때문
훈련과정 : R·파이썬 기반 빅데이터 분석 전문가 양성과정
교과목 평가 : 통계기반 데이터 분석
성명 : 호지수
점수 : 70 / 80 (3번, 7번 틀렸습니다.)
In [1]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
# df 생성 import pandas as pd df = pd.read_csv('../auto-mpg.csv', header=None) df.columns = ['mpg','cylinders','displacement','horsepower','weight', 'acceleration','model year','origin','name'] df.head() |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
Out[1]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 3열 선택3열 다음에 열 추가
- 4열 선택4열 다음에 열 추가
- 5열 선택5열 다음에 열 추가
- 6열 선택6열 다음에 열 추가
- 7열 선택7열 다음에 열 추가
- 8열 선택8열 다음에 열 추가
- 9열 선택9열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
- 4행 선택4행 다음에 행 추가
- 5행 선택5행 다음에 행 추가
열 너비 조절
행 높이 조절
|
|
mpg |
cylinders |
displacement |
horsepower |
weight |
acceleration |
model year |
origin |
name |
|
0 |
18.0 |
8 |
307.0 |
130.0 |
3504.0 |
12.0 |
70 |
1 |
chevrolet chevelle malibu |
|
1 |
15.0 |
8 |
350.0 |
165.0 |
3693.0 |
11.5 |
70 |
1 |
buick skylark 320 |
|
2 |
18.0 |
8 |
318.0 |
150.0 |
3436.0 |
11.0 |
70 |
1 |
plymouth satellite |
|
3 |
16.0 |
8 |
304.0 |
150.0 |
3433.0 |
12.0 |
70 |
1 |
amc rebel sst |
|
4 |
17.0 |
8 |
302.0 |
140.0 |
3449.0 |
10.5 |
70 |
1 |
ford torino |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
Q1. df 데이터프레임에 대하여 아래 사항을 수행하세요. --- (15점)
'mpg','cylinders','displacement','weight','acceleration','model year','origin','name' 컬럼의 통계요약표를 출력
mpg 컬럼의 평균값, 중간값, 최대값, 최소값, 표준편차 각각 개별 출력
mpg 컬럼과 weight컬럼간 상관계수 출력
In [2]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
df2 = df.drop(df.columns[[3,3]], axis=1, inplace=False) display(df2.describe()) print('평균',df2.mpg.mean()) print('중간',df2.mpg.median()) print('최대',df2.mpg.max()) print('최소',df2.mpg.min()) print('표준편차',df2.mpg.std()) df3 = df2[['mpg','weight']] display(df3.corr(),'mpg컬럼과 weight컬럼간 상관계수') |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 3열 선택3열 다음에 열 추가
- 4열 선택4열 다음에 열 추가
- 5열 선택5열 다음에 열 추가
- 6열 선택6열 다음에 열 추가
- 7열 선택7열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
- 4행 선택4행 다음에 행 추가
- 5행 선택5행 다음에 행 추가
- 6행 선택6행 다음에 행 추가
- 7행 선택7행 다음에 행 추가
- 8행 선택8행 다음에 행 추가
열 너비 조절
행 높이 조절
|
|
mpg |
cylinders |
displacement |
weight |
acceleration |
model year |
origin |
|
count |
398.000000 |
398.000000 |
398.000000 |
398.000000 |
398.000000 |
398.000000 |
398.000000 |
|
mean |
23.514573 |
5.454774 |
193.425879 |
2970.424623 |
15.568090 |
76.010050 |
1.572864 |
|
std |
7.815984 |
1.701004 |
104.269838 |
846.841774 |
2.757689 |
3.697627 |
0.802055 |
|
min |
9.000000 |
3.000000 |
68.000000 |
1613.000000 |
8.000000 |
70.000000 |
1.000000 |
|
25% |
17.500000 |
4.000000 |
104.250000 |
2223.750000 |
13.825000 |
73.000000 |
1.000000 |
|
50% |
23.000000 |
4.000000 |
148.500000 |
2803.500000 |
15.500000 |
76.000000 |
1.000000 |
|
75% |
29.000000 |
8.000000 |
262.000000 |
3608.000000 |
17.175000 |
79.000000 |
2.000000 |
|
max |
46.600000 |
8.000000 |
455.000000 |
5140.000000 |
24.800000 |
82.000000 |
3.000000 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
평균 23.514572864321607 중간 23.0 최대 46.6 최소 9.0 표준편차 7.815984312565782
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
열 너비 조절
행 높이 조절
|
|
mpg |
weight |
|
mpg |
1.000000 |
-0.831741 |
|
weight |
-0.831741 |
1.000000 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
'mpg컬럼과 weight컬럼간 상관계수'
Q2. df.horsepower의 통계요약표를 출력하세요. ----- (10점)
In [3]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
df['horsepower'].describe() |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
Out[3]:
count 398 unique 94 top 150.0 freq 22 Name: horsepower, dtype: object
Q3. 아래 사항을 처리 하세요. --- (5점) - 틀림
df.origin 열의 고유값을 출력하세요.
df.origin 열에 대하여 정수형 데이터를 문자형 데이터로 변환한 후 고유값을 출력하세요.
In [4]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
print('df.origin 고유값',df.origin.unique()) dfo = df.origin.astype('object') print('df.origin열을 문자형 데이터로 변환한 후 고유값 출력',dfo.unique()) |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
df.origin 고유값 [1 3 2] df.origin열을 문자형 데이터로 변환한 후 고유값 출력 [1 3 2]
In [5]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
print((df.origin).dtype) # origin 열의 고유값 확인 print(df['origin'].unique())
# 정수형 데이터를 문자형 데이터로 변환 df['origin'].replace({1:'USA', 2:'EU', 3:'JAPAN'}, inplace=True)
print(df['origin'].unique()) |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
int64 [1 3 2] ['USA' 'JAPAN' 'EU']
Q4. origin 열의 자료형을 확인하고 범주형으로 변환하여 출력하세요. --- (5점)
In [6]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
print(df['origin'].dtypes) |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
object
In [7]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
print('origin 열 타입 :',type(df['origin'])) dfc = df['origin'].astype('category') display(dfc.head()) |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
origin 열 타입 : <class 'pandas.core.series.Series'>
0 USA 1 USA 2 USA 3 USA 4 USA Name: origin, dtype: category Categories (3, object): [EU, JAPAN, USA]
Q5. origin 열을 범주형에서 문자열로 변환한 후 자료형을 출력하세요. --- (5점)
In [8]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
dfs = df['origin'].astype('object') display(dfs.dtypes) display(type(dfs)) display(type(dfs.dtypes)) |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
dtype('O')
pandas.core.series.Series
numpy.dtype
Q6. df.horsepower를 범주형(카테고리) 데이터 처리한 후 아래와 같이 출력하세요. --- (5점)
horsepower hp_bin\ 0 130.0 보통출력\ 1 165.0 보통출력\ 2 150.0 보통출력\ 3 150.0 보통출력\ 4 140.0 보통출력
In [9]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
import numpy as np
df['horsepower'].replace('?', np.nan, inplace=True) df.dropna(subset=['horsepower'], axis=0, inplace=True) df['horsepower'] = df['horsepower'].astype('float') df['hp'] = df['horsepower'].astype('int')
count, bin_dividers = np.histogram(df['horsepower'], bins=3) print(count) # display(bin_dividers) print()
bin_names = ['저출력', '보통출력', '고출력']
df['hp_bin'] = pd.cut(x=df['horsepower'], bins=bin_dividers, labels=bin_names, include_lowest=True)
display(df[['horsepower', 'hp_bin']].head()) |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
[257 103 32]
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
- 4행 선택4행 다음에 행 추가
- 5행 선택5행 다음에 행 추가
열 너비 조절
행 높이 조절
|
|
horsepower |
hp_bin |
|
0 |
130.0 |
보통출력 |
|
1 |
165.0 |
보통출력 |
|
2 |
150.0 |
보통출력 |
|
3 |
150.0 |
보통출력 |
|
4 |
140.0 |
보통출력 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
Q7. hp_bin 열의 범주형 데이터를 숫자형 범주로 변환하여 앞에서 15개만 출력하세요. --- (5점) - 틀림
In [10]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
horsepower_dummies = pd.get_dummies(df['hp_bin']) horsepower_dummies.head(15) |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
Out[10]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 3열 선택3열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
- 4행 선택4행 다음에 행 추가
- 5행 선택5행 다음에 행 추가
- 6행 선택6행 다음에 행 추가
- 7행 선택7행 다음에 행 추가
- 8행 선택8행 다음에 행 추가
- 9행 선택9행 다음에 행 추가
- 10행 선택10행 다음에 행 추가
- 11행 선택11행 다음에 행 추가
- 12행 선택12행 다음에 행 추가
- 13행 선택13행 다음에 행 추가
- 14행 선택14행 다음에 행 추가
- 15행 선택15행 다음에 행 추가
열 너비 조절
행 높이 조절
|
|
저출력 |
보통출력 |
고출력 |
|
0 |
0 |
1 |
0 |
|
1 |
0 |
1 |
0 |
|
2 |
0 |
1 |
0 |
|
3 |
0 |
1 |
0 |
|
4 |
0 |
1 |
0 |
|
5 |
0 |
0 |
1 |
|
6 |
0 |
0 |
1 |
|
7 |
0 |
0 |
1 |
|
8 |
0 |
0 |
1 |
|
9 |
0 |
0 |
1 |
|
10 |
0 |
0 |
1 |
|
11 |
0 |
1 |
0 |
|
12 |
0 |
1 |
0 |
|
13 |
0 |
0 |
1 |
|
14 |
1 |
0 |
0 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
In [11]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
# 풀이 from sklearn import preprocessing
# 전처리를 위한 encoder 객체 만들기 le = preprocessing.LabelEncoder() result = le.fit_transform(df.hp_bin.head(15)) print(result) |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
[1 1 1 1 1 0 0 0 0 0 0 1 1 0 2]
Q8. stock-data.csv를 불러와서 아래사항을 수행하세요. --- (10점)
object 자료형으로 되어있는 Date 컬럼을 datetime64 자료형으로 변환
new_Date 컬럼을 생성한 후 다시 인덱스로 셋팅하고 기존 Date는 삭제한 후 출력
In [12]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
df = pd.read_csv('../stock-data.csv') df['Date'] = pd.to_datetime(df['Date']) display(df.info()) # datetime64 자료형으로 변환
df['new_Date'] = pd.to_datetime(df['Date']) display(df.info()) # new_Date 컬럼 생성 확인
df.set_index('new_Date', inplace=True) # new_Date 컬럼을 인덱스로 지정 df.drop('Date', axis=1, inplace=True) # 기존 Date 컬럼 삭제 display(df.head()) # 출력 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
<class 'pandas.core.frame.DataFrame'> RangeIndex: 20 entries, 0 to 19 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Date 20 non-null datetime64[ns] 1 Close 20 non-null int64 2 Start 20 non-null int64 3 High 20 non-null int64 4 Low 20 non-null int64 5 Volume 20 non-null int64 dtypes: datetime64[ns](1), int64(5) memory usage: 1.1 KB
None
<class 'pandas.core.frame.DataFrame'> RangeIndex: 20 entries, 0 to 19 Data columns (total 7 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Date 20 non-null datetime64[ns] 1 Close 20 non-null int64 2 Start 20 non-null int64 3 High 20 non-null int64 4 Low 20 non-null int64 5 Volume 20 non-null int64 6 new_Date 20 non-null datetime64[ns] dtypes: datetime64[ns](2), int64(5) memory usage: 1.2 KB
None
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 3열 선택3열 다음에 열 추가
- 4열 선택4열 다음에 열 추가
- 5열 선택5열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
- 4행 선택4행 다음에 행 추가
- 5행 선택5행 다음에 행 추가
- 6행 선택6행 다음에 행 추가
열 너비 조절
행 높이 조절
|
|
Close |
Start |
High |
Low |
Volume |
|
new_Date |
|
|
|
|
|
|
2018-07-02 |
10100 |
10850 |
10900 |
10000 |
137977 |
|
2018-06-29 |
10700 |
10550 |
10900 |
9990 |
170253 |
|
2018-06-28 |
10400 |
10900 |
10950 |
10150 |
155769 |
|
2018-06-27 |
10900 |
10800 |
11050 |
10500 |
133548 |
|
2018-06-26 |
10800 |
10900 |
11000 |
10700 |
63039 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
Q9. stock-data.csv를 불러와서 아래 사항을 수행한 후 월별 데이터를 작성하여 출력하세요. --- (10점)
object 자료형으로 되어있는 Date 컬럼을 datetime64 자료형으로 변환하여 new_Date 컬럼을 생성
dt 속성을 이용하여 period로 변환, 월단위 기간을 의미하는 Date_m 컬럼을 생성하고 인덱스로 지정
In [13]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
# 날짜 데이터 분리 import pandas as pd # read_csv() 함수로 파일 읽어와서 df로 변환 df = pd.read_csv('../stock-data.csv')
# 문자열인 날짜 데이터를 판다스 Timestamp 로 변환 df['new_Date'] = pd.to_datetime(df['Date']) # df에 새로운 열로 추가
# dt 속성을 이용하여 new_Date 열의 정보를 월로 구분 df['Month'] = df['new_Date'].dt.month display(df.head(3))
# Timestamp를 Period로 변환하여 월 표기 변경하기 df['Date_m'] = df['new_Date'].dt.to_period(freq='M') display(df.head(3))
# 원하는 열을 새로운 행 인덱스로 지정 df.set_index('Date_m', inplace=True) display(df.head(3)) |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 3열 선택3열 다음에 열 추가
- 4열 선택4열 다음에 열 추가
- 5열 선택5열 다음에 열 추가
- 6열 선택6열 다음에 열 추가
- 7열 선택7열 다음에 열 추가
- 8열 선택8열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
열 너비 조절
행 높이 조절
|
|
Date |
Close |
Start |
High |
Low |
Volume |
new_Date |
Month |
|
0 |
2018-07-02 |
10100 |
10850 |
10900 |
10000 |
137977 |
2018-07-02 |
7 |
|
1 |
2018-06-29 |
10700 |
10550 |
10900 |
9990 |
170253 |
2018-06-29 |
6 |
|
2 |
2018-06-28 |
10400 |
10900 |
10950 |
10150 |
155769 |
2018-06-28 |
6 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 3열 선택3열 다음에 열 추가
- 4열 선택4열 다음에 열 추가
- 5열 선택5열 다음에 열 추가
- 6열 선택6열 다음에 열 추가
- 7열 선택7열 다음에 열 추가
- 8열 선택8열 다음에 열 추가
- 9열 선택9열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
열 너비 조절
행 높이 조절
|
|
Date |
Close |
Start |
High |
Low |
Volume |
new_Date |
Month |
Date_m |
|
0 |
2018-07-02 |
10100 |
10850 |
10900 |
10000 |
137977 |
2018-07-02 |
7 |
2018-07 |
|
1 |
2018-06-29 |
10700 |
10550 |
10900 |
9990 |
170253 |
2018-06-29 |
6 |
2018-06 |
|
2 |
2018-06-28 |
10400 |
10900 |
10950 |
10150 |
155769 |
2018-06-28 |
6 |
2018-06 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 3열 선택3열 다음에 열 추가
- 4열 선택4열 다음에 열 추가
- 5열 선택5열 다음에 열 추가
- 6열 선택6열 다음에 열 추가
- 7열 선택7열 다음에 열 추가
- 8열 선택8열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
- 4행 선택4행 다음에 행 추가
열 너비 조절
행 높이 조절
|
|
Date |
Close |
Start |
High |
Low |
Volume |
new_Date |
Month |
|
Date_m |
|
|
|
|
|
|
|
|
|
2018-07 |
2018-07-02 |
10100 |
10850 |
10900 |
10000 |
137977 |
2018-07-02 |
7 |
|
2018-06 |
2018-06-29 |
10700 |
10550 |
10900 |
9990 |
170253 |
2018-06-29 |
6 |
|
2018-06 |
2018-06-28 |
10400 |
10900 |
10950 |
10150 |
155769 |
2018-06-28 |
6 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
Q10. df.mpg를 정규화 수행한 후 수행전과 후의 통계요약표를 출력하세요. --- (10점)
In [14]:
셀 전체 선택
- 0열 선택0열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
열 너비 조절
행 높이 조절
|
df = pd.read_csv('../auto-mpg.csv', header=None) df.columns = ['mpg','cylinders','displacement','horsepower','weight', 'acceleration','model year','origin','name'] display(df.mpg.describe()) # 정규화 수행 전 통계요약표
df.mpg = df.mpg / abs(df.mpg.max()) display(df.mpg.describe()) # 정규화 수행 후 통계요약표 |
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
count 398.000000 mean 23.514573 std 7.815984 min 9.000000 25% 17.500000 50% 23.000000 75% 29.000000 max 46.600000 Name: mpg, dtype: float64
count 398.000000 mean 0.504605 std 0.167725 min 0.193133 25% 0.375536 50% 0.493562 75% 0.622318 max 1.000000 Name: mpg, dtype: float64
'PYTHON' 카테고리의 다른 글
| 20200327 - 파이썬 머신러닝(얼굴 자동 모자이크, 당뇨병 예측, 분류 평가) (0) | 2020.03.27 |
|---|---|
| 20200326 - 파이썬 머신러닝 - 타이타닉 생존자 예측 (0) | 2020.03.26 |
| 20200325-1 파이썬 머신러닝 (CT 촬영(폐) 원하는 부분 추출) (0) | 2020.03.25 |
| 20200324 - 파이썬 빅데이터 시각화 (0) | 2020.03.24 |
| 20200323 - 파이썬 탐색적 데이터 분석 - 전처리, 그룹 연산 (0) | 2020.03.23 |




댓글