대표사진 삭제
7번 작업까지만 한 것
(1) 대통령별 목록 보기
-대통령 기록관(http://pa.go.kr/index.jsp)
-기록물정보/검색 → 대통령별 콘텐츠’에서 ‘김영삼대통령’ 클릭
(2) 대통령별 콘텐츠 보기
-콘텐츠 구성 항목에서 대통령의 ‘연설기록’ 선택
(3) 대통령 연설문 목록 보기
-연설기록 목록에서 ‘제14대 대통령 취임사’ 선택
(4) 대통령 취임사 내용 보기 및 파일 저장
-취임사 내용 전체를 마우스로 선택하여 복사한 후 speech.txt로 저장
대표사진 삭제
사진 설명을 입력하세요.
대표사진 삭제
사진 설명을 입력하세요.
대표사진 삭제
사진 설명을 입력하세요.
전송중...
사진 설명을 입력하세요.
전송중...
사진 설명을 입력하세요.
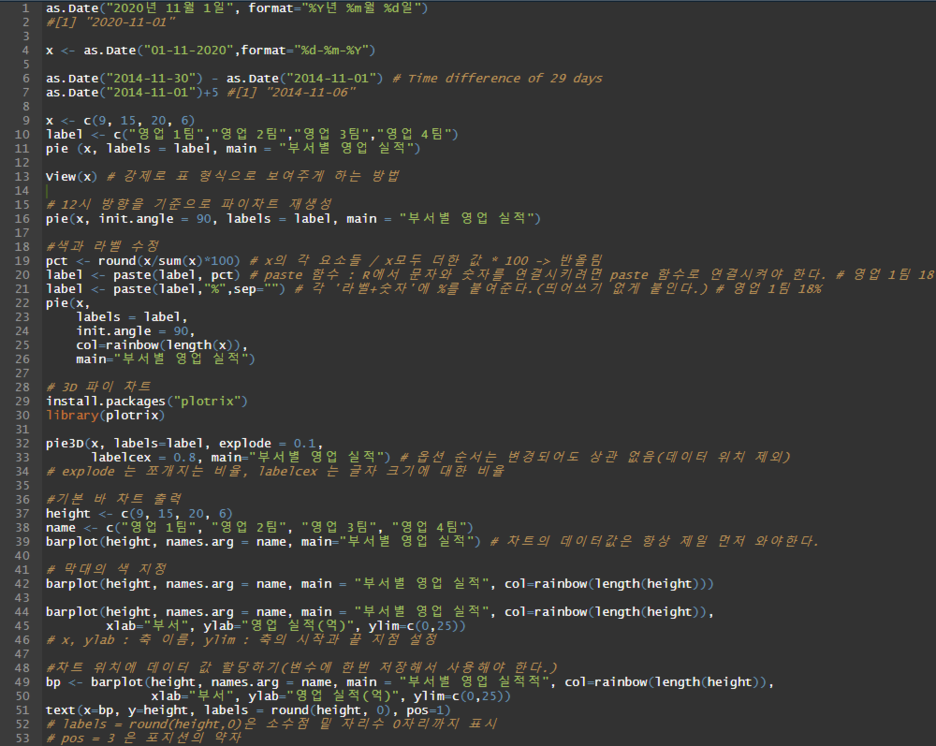
as.Date("2020년 11월 1일", format="%Y년 %m월 %d일")
#[1] "2020-11-01"
x <- as.Date("01-11-2020",format="%d-%m-%Y")
as.Date("2014-11-30") - as.Date("2014-11-01") # Time difference of 29 days
as.Date("2014-11-01")+5 #[1] "2014-11-06"
x <- c(9, 15, 20, 6)
label <- c("영업 1팀","영업 2팀","영업 3팀","영업 4팀")
pie (x, labels = label, main = "부서별 영업 실적")
View(x) # 강제로 표 형식으로 보여주게 하는 방법
# 12시 방향을 기준으로 파이차트 재생성
pie(x, init.angle = 90, labels = label, main = "부서별 영업 실적")
#색과 라벨 수정
pct <- round(x/sum(x)*100) # x의 각 요소들 / x모두 더한 값 * 100 -> 반올림
label <- paste(label, pct) # paste 함수 : R에서 문자와 숫자를 연결시키려면 paste 함수로 연결시켜야 한다. # 영업 1팀 18
label <- paste(label,"%",sep="") # 각 '라벨+숫자'에 %를 붙여준다.(띄어쓰기 없게 붙인다.) # 영업 1팀 18%
pie(x,
labels = label,
init.angle = 90,
col=rainbow(length(x)),
main="부서별 영업 실적")
# 3D 파이 차트
install.packages("plotrix")
library(plotrix)
pie3D(x, labels=label, explode = 0.1,
labelcex = 0.8, main="부서별 영업 실적") # 옵션 순서는 변경되어도 상관 없음(데이터 위치 제외)
# explode 는 쪼개지는 비율, labelcex 는 글자 크기에 대한 비율
#기본 바 차트 출력
height <- c(9, 15, 20, 6)
name <- c("영업 1팀", "영업 2팀", "영업 3팀", "영업 4팀")
barplot(height, names.arg = name, main="부서별 영업 실적") # 차트의 데이터값은 항상 제일 먼저 와야한다.
# 막대의 색 지정
barplot(height, names.arg = name, main = "부서별 영업 실적", col=rainbow(length(height)))
barplot(height, names.arg = name, main = "부서별 영업 실적", col=rainbow(length(height)),
xlab="부서", ylab="영업 실적(억)", ylim=c(0,25))
# x, ylab : 축 이름, ylim : 축의 시작과 끝 지점 설정
#차트 위치에 데이터 값 할당하기(변수에 한번 저장해서 사용해야 한다.)
bp <- barplot(height, names.arg = name, main = "부서별 영업 실적적", col=rainbow(length(height)),
xlab="부서", ylab="영업 실적(억)", ylim=c(0,25))
text(x=bp, y=height, labels = round(height, 0), pos=1)
# labels = round(height,0)은 소수점 밑 자리수 0자리까지 표시
# pos = 3 은 포지션의 약자
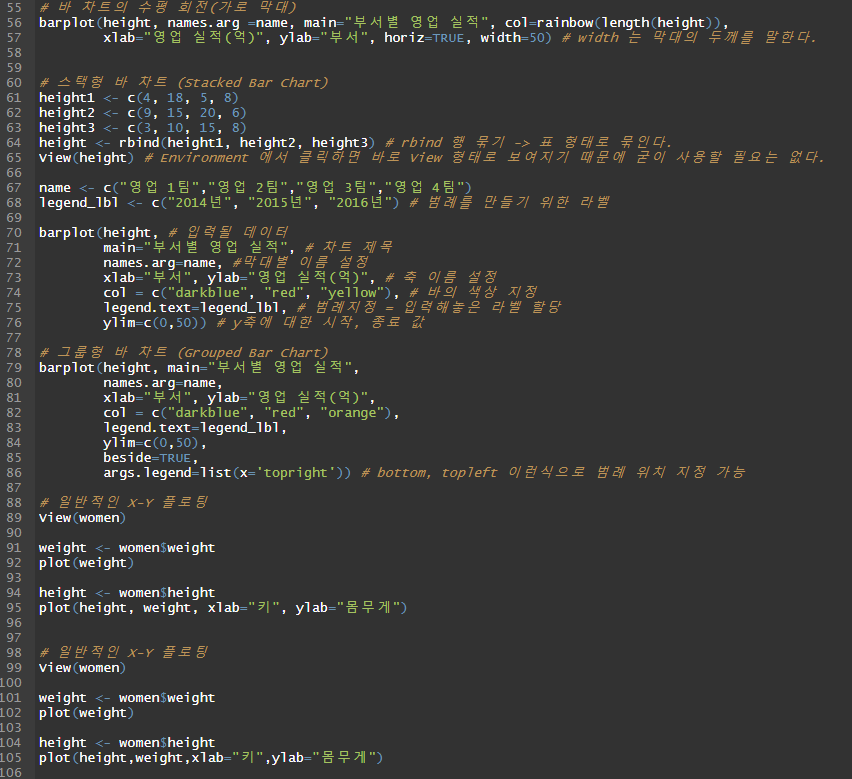
# 바 차트의 수평 회전(가로 막대)
barplot(height, names.arg =name, main="부서별 영업 실적", col=rainbow(length(height)),
xlab="영업 실적(억)", ylab="부서", horiz=TRUE, width=50) # width 는 막대의 두께를 말한다.
# 스택형 바 차트 (Stacked Bar Chart)
height1 <- c(4, 18, 5, 8)
height2 <- c(9, 15, 20, 6)
height3 <- c(3, 10, 15, 8)
height <- rbind(height1, height2, height3) # rbind 행 묶기 -> 표 형태로 묶인다.
View(height) # Environment 에서 클릭하면 바로 View 형태로 보여지기 때문에 굳이 사용할 필요는 없다.
name <- c("영업 1팀","영업 2팀","영업 3팀","영업 4팀")
legend_lbl <- c("2014년", "2015년", "2016년") # 범례를 만들기 위한 라벨
barplot(height, # 입력될 데이터
main="부서별 영업 실적", # 차트 제목
names.arg=name, #막대별 이름 설정
xlab="부서", ylab="영업 실적(억)", # 축 이름 설정
col = c("darkblue", "red", "yellow"), # 바의 색상 지정
legend.text=legend_lbl, # 범례지정 = 입력해놓은 라벨 할당
ylim=c(0,50)) # y축에 대한 시작, 종료 값
# 그룹형 바 차트 (Grouped Bar Chart)
barplot(height, main="부서별 영업 실적",
names.arg=name,
xlab="부서", ylab="영업 실적(억)",
col = c("darkblue", "red", "orange"),
legend.text=legend_lbl,
ylim=c(0,50),
beside=TRUE,
args.legend=list(x='topright')) # bottom, topleft 이런식으로 범례 위치 지정 가능
# 일반적인 X-Y 플로팅
View(women)
weight <- women$weight
plot(weight)
height <- women$height
plot(height, weight, xlab="키", ylab="몸무게")
# 일반적인 X-Y 플로팅
View(women)
weight <- women$weight
plot(weight)
height <- women$height
plot(height,weight,xlab="키",ylab="몸무게")
# 플로팅 문자의 출력
plot(height,weight,xlab="키",ylab="몸무게",pch=23,col="blue",bg="yellow",cex=1.5)
# 지진의 강도에 대한 히스토그램
head(quakes)
mag <- quakes$mag
mag
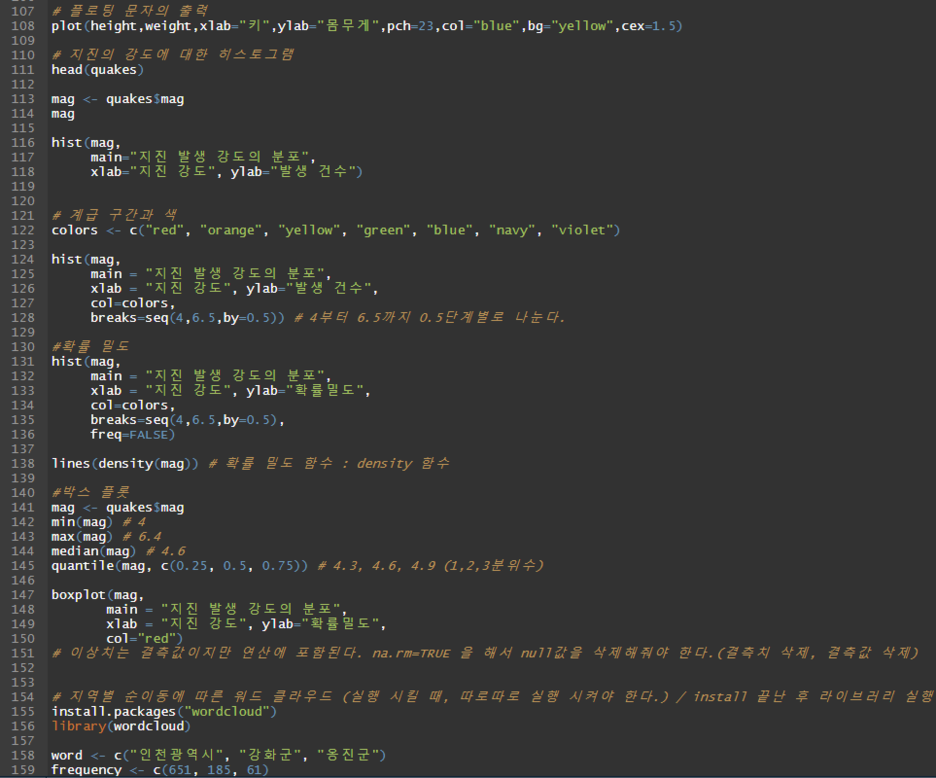
hist(mag,
main="지진 발생 강도의 분포",
xlab="지진 강도", ylab="발생 건수")
# 계급 구간과 색
colors <- c("red", "orange", "yellow", "green", "blue", "navy", "violet")
hist(mag,
main = "지진 발생 강도의 분포",
xlab = "지진 강도", ylab="발생 건수",
col=colors,
breaks=seq(4,6.5,by=0.5)) # 4부터 6.5까지 0.5단계별로 나눈다.
#확률 밀도
hist(mag,
main = "지진 발생 강도의 분포",
xlab = "지진 강도", ylab="확률밀도",
col=colors,
breaks=seq(4,6.5,by=0.5),
freq=FALSE)
lines(density(mag)) # 확률 밀도 함수 : density 함수
#박스 플롯
mag <- quakes$mag
min(mag) # 4
max(mag) # 6.4
median(mag) # 4.6
quantile(mag, c(0.25, 0.5, 0.75)) # 4.3, 4.6, 4.9 (1,2,3분위수)
boxplot(mag,
main = "지진 발생 강도의 분포",
xlab = "지진 강도", ylab="확률밀도",
col="red")
# 이상치는 결측값이지만 연산에 포함된다. na.rm=TRUE 을 해서 null값을 삭제해줘야 한다.(결측치 삭제, 결측값 삭제)
# 지역별 순이동에 따른 워드 클라우드 (실행 시킬 때, 따로따로 실행 시켜야 한다.) / install 끝난 후 라이브러리 실행
install.packages("wordcloud")
library(wordcloud)
word <- c("인천광역시", "강화군", "옹진군")
frequency <- c(651, 185, 61)
# 단어와 노출 빈도수를 임의로 설정하였다.
# 첫 번째 값은 표현할 단어들, 두 번째 값이 각 단어에 대한 노출 빈도 수, 나머지는 옵션
wordcloud(word, frequency, colors="blue")
#단어들의 색 변환
wordcloud(word,
frequency,
random.order= F,
ramdom.color= F,
colors = rainbow(length(word))
)
#다양한 단어 색 출력을 위한 파레트 패키지의 활용
install.packages("RColorBrewer")
library(RColorBrewer)
pal2 <- brewer.pal(8, "Dark2")
word <- c("인천광역시", "강화군", "옹진군")
frequency <- c(651, 86, 61)
wordcloud(word, frequency, colors=pal2)
# 다운로드 사이트 : http://kostat.go.kr
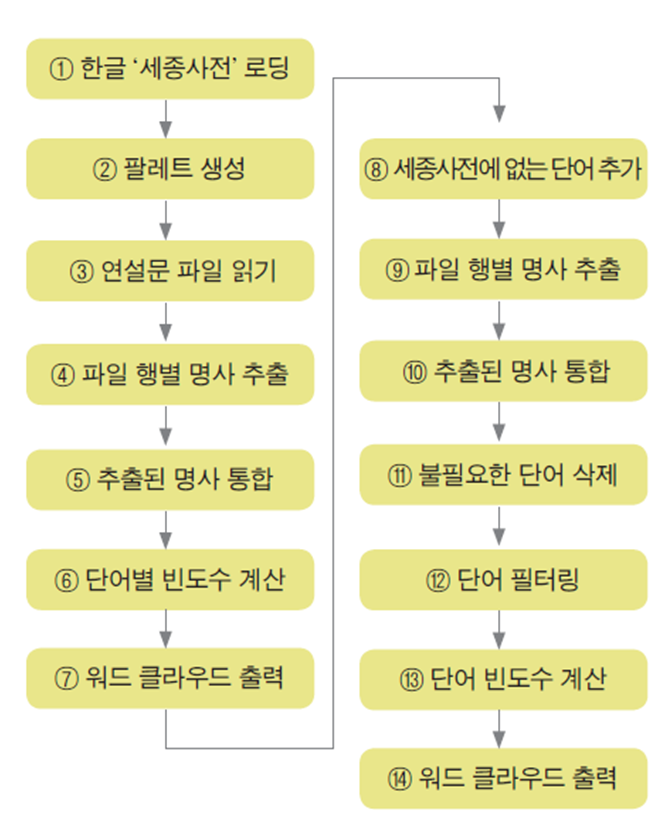
# 작업 순서
# 1. 데이터 파일 읽기 : 6_101_DT_1B26001_A01_M.csv
# 2. '전국' 지역이 아닌 데이터만 추출
# 3. 행정구역 중 '구' 단위에 해당하는 행 번호 추출
# 4. '구' 지역 데이터 제외
# 5. 순이동 인구수가 0보다 큰지역 추출
# 6. 단어(행정 구역) 할당
# 7. 워드클라우드 출력
# 1. 데이터 파일 읽기 : read.csv(file.choose(), header=T)
# 2. '전국' 지역이 아닌 데이터만 추출('전국' 지역 데이터 제외) : data[data$행정구역.시군구.별 != "전국", ]
# 3. 행정구역 중 '구' 단위에 해당하는 행 번호 추출 : grep("구$", data2$행정구역.시군구.별)
# 4. '구' 지역 데이터 제외 : <- data2[-c(x), ]
# 5. 순이동 인구수가 0보다 큰지역 추출 : data3[data3$순이동.명>0, ]
# 6. 단어(행정 구역) 할당 : data4$행정구역.시군구.별
# 7. 행정구역별 빈도 : data4$순이동.명
# 8. 워드클라우드 출력 : wordcloud()
data <- read.csv(file.choose(), header=T) # 모든 괄호가 .으로 변경된다.
View(data)
head(data) # read 가 끝나야 head를 사용할 수 있다.
names(data) # 데이터의 컬럼 확인
# ()가 R에서는 모두 .으로 바뀌어서 들어온다.
data2 <- data[data$행정구역.시군구.별 != "전국", ] # 전체 데이터$컬럼명 중에서 != "전국" 데이터가 아닌 것만 모두 선택
x <- grep("구$", data2$행정구역.시군구.별) # grep함수 : 지정 조건에 맞는 '행 번호'를 벡터로 반환(x: 구 관련 행번호만 저장)
data3 <- data2[-c(x), ] # '구' 지역 데이터 제외
head(data3)
data4 <- data3[data3$순이동.명>0, ] # data3중 순이동.명 컬럼 중 0보다 큰애들만 추출
head(data4)
word <- data4$행정구역.시군구.별 # 워드클라우드작업을 위한 글자 데이터만 추출
frequency <- data4$순이동.명 # 숫자값으로 작업할 숫자 데이터만 추출
library(wordcloud)
library(RColorBrewer)
pal2 <- brewer.pal(8, "Dark2")
wordcloud(word,frequency, colors=pal2)
전송중...
사진 설명을 입력하세요.
#연설문의 단어에 대한 워드 클라우드 만들기
install.packages("KoNLP")
install.packages("RColorBrewer")
install.packages("wordcloud")
library(KoNLP)
library(RColorBrewer)
library(wordcloud)
useSejongDic()
pal2 <- brewer.pal(8, "Dark2")
text <- readLines(file.choose()) # 문서를 줄단위로 읽어주는 함수 : readLines() 엔터친 위치를 기준으로 줄단위로 읽어오는 함수
text # 줄단위로 읽은 벡터를 텍스트에 집어넣고
# 리스트 타입의 데이터를 factor 형태로 반환하기가 힘들다. 그래서
# extractNoun 이 명사를 찾아서 추출하는 역할(띄어쓰기도 있으면 띄어쓰기도 다 구분한다.), 그 결과를 sapply가 list형태로 반환
# text : 벡터가 가진 것들 중에서 , USE.NAMES : extractNoun 을 통해서 USE.NAMES를 실행
noun <- sapply(text, extractNoun, USE.NAMES = F)
noun
# list 타입의 데이터를 수치형으로 변환
noun2 <- unlist(noun)
noun2
# p.221
word_count <- table(noun2) # 테이블을 하면 팩터로 바꿔준다. # 쪼개진 단어들의 갯수를 파악하여 테이블로 반환
word_count # 단어의 빈도수를 가지고 있음.
head(sort(word_count, decreasing = TRUE), 10) #정렬해주고 상위 10개만 꺼내온다.
wordcloud(names(word_count), # names 라는 함수를 이용해서 단어를 꺼내고
freq=word_count, # freq 옵션을 이용해서 글자나 숫자를 꺼낼 수 있다.
scale=c(6,0.3), # 가장 큰값을 6, 가장 작은 값을 0.3의 비율로 맞춘다.
min.freq=3, # 최소 빈도수를 3 이상으로 잡는다.(1이나 2는 표기하지않는다.)
random.order= F, # 실행할때마다 위치 변경
rot.per = .1, # 회전 각도값을 0.1 비율로 회전시킨다.
colors=pal2) # 글자 색 변경
메모
R - studio
Connection 탭 : 외부와 연결할 경우 사용
우측 하단 Files : 작업폴더, ...내부에 Data폴더 생성 및 파일 생성 & 삭제
Plot : 차트 관련 화면이 나오는 곳
Packages : 기본적으로 설치된 패키지 리스트가 나온다.(체크된건 라이브러리 함수가 실행되어있는 애들) - 체크 해제하면 디테치
- intall - 첫글자 입력하면 패키지 리스트가 나온다.
- update : 내가 설치한 패키지를 새로 업데이트하고싶을 경우
Help : 함수에 대해 검색하면 사용 방법 및 옵션 리스트가 출력된다.
날짜 형식 지정
%d : 일자를 숫자로 인식
%m : 월을 숫자로 인식
%b : 월을 영어 약어로 인식
%B : 월을 전체 이름으로 인식
%y : 연도를 숫자 두 자리로 인식
%Y : 연도를 숫자 네 자리로 인식
as.Date("2020년 11월 1일", format="%Y년 %m월 %d일")
x<-as.Date("01-11-2020",format="%d-%m-%Y") 하게되면 Environment에 x값이 할당된다.
# 날짜와 날짜 연산 가능
as.Date("2014-11-30" - as.Date("2014-11-01")
Time difference of 29 days
# 날짜와 일반 숫자 연산 가능
as.Date("2014-11-01")+5
***R 셋팅 > 패키지 설치
packages > install > plotrix 검색 > install > 패키지 검색부분에서 plotrix > 체크
>>>> history 탭을 눌러보면 해당 라이브러리를 로딩했다 라고 히스토리가 쌓이게 됨.
http://kostat.go.kr/portal/korea/index.action: 데이터 다운받는 사이트
통계청 - 국가통계포털 - 가운데 데이터 카테고리 중 원하는 카테고리 선택(우리가 쓰는 데이터는 인구&가구>국내인구이동통계>시군구별 이동자수) -
## 분석 할 때 )
1. 데이터 전처리 작업 : xlsx 같은 경우 엑셀 프로그램을 이용해서 1차적인 전처리를 할 수 있다.
(엑셀 프로그램이 데이터를 다 읽지 못하는 경우(너무커서)에는 R내부로 읽어와서 전처리작업을 해야 한다.)
2. 항상 데이터를 먼저 확인(원본 데이터에 컬럼명이 있는 경우 헤더명을 가지고 와야 한다.)
# 다운로드 사이트 : http://kostat.go.kr
# 작업 순서
# 1. 데이터 파일 읽기 : 6_101_DT_1B26001_A01_M.csv
# 2. '전국' 지역이 아닌 데이터만 추출
# 3. 행정구역 중 '구' 단위에 해당하는 행 번호 추출
# 4. '구' 지역 데이터 제외
# 5. 순이동 인구수가 0보다 큰지역 추출
# 6. 단어(행정 구역) 할당
# 7. 워드클라우드 출력
# 1. 데이터 파일 읽기 : read.csv(file.choose(), header=T)
# 2. '전국' 지역이 아닌 데이터만 추출('전국' 지역 데이터 제외) : data[data$행정구역.시군구.별 != "전국", ]
# 3. 행정구역 중 '구' 단위에 해당하는 행 번호 추출 : grep("구$", data2$행정구역.시군구.별)
# 4. '구' 지역 데이터 제외 : <- data2[-c(x), ]
# 5. 순이동 인구수가 0보다 큰지역 추출 : data3[data3$순이동.명>0, ]
# 6. 단어(행정 구역) 할당 : data4$행정구역.시군구.별
# 7. 행정구역별 빈도 : data4$순이동.명
# 8. 워드클라우드 출력 : wordcloud()
'PYTHON' 카테고리의 다른 글
| 20200402 - R (데이터 전처리, 변수 간 관계 분석 - 직업별 월급 차이 ) (0) | 2020.04.02 |
|---|---|
| 20200401 - R 차트 그리기, 상관관계 분석, 삶의 질 평가 실습 (0) | 2020.04.01 |
| 20200330 - R 기초 문법 (연산자, 차트, 패키지, 데이터 기초) (0) | 2020.03.30 |
| 20200327 - 파이썬 머신러닝(얼굴 자동 모자이크, 당뇨병 예측, 분류 평가) (0) | 2020.03.27 |
| 20200326 - 파이썬 머신러닝 - 타이타닉 생존자 예측 (0) | 2020.03.26 |


댓글